

Prognostic study of mild cognitive impairment progressing to Alzheimer′s disease based on polygenic risk score and machine learning modeling strategy
-
摘要:
目的 本研究从全基因组和候选基因组的角度探究多基因风险评分(polygenic risk score, PRS)与机器学习对轻度认知障碍(mild cognitive impairment, MCI)发展为阿尔茨海默病(alzheimer′s disease, AD)的预后预测性能, 为MCI发展为AD的第5年预后预测建模提供更有力的方法理论依据。 方法 借助聚类与阈值(clumping and thresholding, C+T)、多基因风险评分-连续收缩(polygenic risk scores-continuous shrinkage, PRS-CS)、随机生存森林(random survival forest, RSF)、生存支持向量机(survival support vector machine, SSVM)4种常用统计方法对MCI发展为AD的第5年生存情况进行预测建模。利用C+T与PRS-CS得到的AD遗传风险得分作为独立的预测因子纳入Cox比例风险回归模型, RSF与SSVM则从候选基因组角度直接纳入所有与AD有关的单核苷酸多态性(single nucleotide polymorphism, SNPs)进行统计建模。最后, 采用C指数作为模型预测效果的评价指标。 结果 无论是C+T还是PRS-CS方法, 在全基因组和候选基因组两种情况下的C指数差值均 < 0.01, 而两种方法的C指数差值最大为0.04, 二者差异均无统计学意义; 机器学习的方法明显好于PRS方法, RSF和SSVM的C指数均能达到0.76, 较C+T、PRS-CS高0.07、0.11, 差异有统计学意义(均P < 0.05)。 结论 机器学习方法表现优异, 为MCI发展为AD的预后预测提供了更为可行的统计建模方案。 Abstract:Objective To provide the theoretical basis for modeling the fifth-year prognostic prediction of the conversion from mild cognitive impairment (MCI) to alzheimer′s disease (AD), this study explored the prognostic prediction performance of polygenic risk score and machine learning methods on the progression from MCI to AD from the perspective of whole genome and candidate genome. Methods Using clumping and thresholding (C+T), polygenic risk scores-continuous shrinkage (PRS-CS), random survival forest (RSF), and survival support vector machine (SSVM) to predict the fifth-year prognostic prediction of patients who progressed from MCI to AD.The polygenic risk score of AD obtained by C+T and PRS-CS were included as independent predictors in Cox proportional hazards regression model, while RSF and SSVM were directly included in all single nucleotide polymorphisms (SNPs) related to AD from the perspective of candidate genome for statistical modeling.Finally, C-index was used as the evaluation index of the prediction effect of the model. Results The difference in C-index between the whole genome and candidate genome was less than 0.01 for both C+T and PRS-CS methods, while the maximum difference of C-index between the two methods was 0.04, and there was no statistical difference between them.The machine learning methods significantly outperformed the PRS methods.The C-index of RSF and SSVM reached 0.76, indicating significance increases of 0.07 and 0.11 over C+T and PRS-CS, respectively (all P < 0.05). Conclusions Machine learning methods perform well and provide a more feasible statistical modeling scheme for the prognostic prediction of the progression of MCI to AD. -
阿尔茨海默病(alzheimer′s disease, AD)是一种神经退行性疾病,是痴呆最常见的一种临床类型[1]。轻度认知障碍(mild cognitive impairment, MCI)是介于正常衰老和痴呆之间的认知障碍的中间状态。每年大约有8%~15%的MCI个体发展为AD,同时超过50%的MCI患者会在5年内发展为AD[2],在该时间节点前对有可能发展为AD的高危人群进行预测、识别及干预,可有效控制AD的发生发展[3]。但MCI患者的单核苷酸多态性(single nucleotide polymorphism, SNPs)与AD高危人群更为接近,使得从遗传信息角度区分MCI和AD存在困难,给预后预测的建模带来了极大的挑战。
目前,关于MCI发展为AD的常用预测建模方法主要包括多基因风险评分(polygenic risk score, PRS)和机器学习方法[4],但二者建模策略完全不同:PRS方法通过将SNPs整合成评分并将其作为变量纳入Cox比例风险回归模型,从而实现预后预测;机器学习方法则通过一定条件筛选SNPs,将保留下的SNPs作为变量纳入模型进行预测。
借助PRS预测AD的遗传风险,包括全基因组和候选基因组两个角度。全基因组纳入了预处理后全部的等位基因信息,但同时也纳入过多的噪声SNPs;而候选基因组噪声SNPs较全基因少,但有可能遗漏重要的遗传因子[5]。本研究以阿尔茨海默病神经成像倡议数据库(the alzheimer′s disease neuroimaging initiative, ADNI,
http://adni.loni.ucla.edu )中测得的SNPs作为全基因组,以公开报道的95个与AD相关的基因作为候选基因组展开后续研究[6]。借助聚类与阈值(clumping and thresholding, C+T)与多基因风险评分-连续收缩(polygenic risk scores-continuous shrinkage, PRS-CS)是最常用的PRS建模方法,但二者对于纳入模型的SNPs的效应值处理方式不同:C+T方法通过使用来自全基因组汇总数据的效应值计算PRS[7];PRS-CS利用全基因组汇总数据和外部连锁不平衡参考面板推断SNPs的后验效应[8]。由于SNPs间存在高相关性,且在计算PRS过程中会纳入较多噪声SNPs,将该PRS作为变量纳入Cox比例风险回归模型会对其预后预测性能造成一定影响。因此直接利用高贡献度的SNPs进行预后预测也许会有更好的预测效果,但Cox比例风险模型等传统模型无法对高维度、强相关的基因数据进行预后预测。Ishwaran等[9]提出的随机生存森林(random survival forest, RSF)方法和Evers等[10]提出的生存支持向量机(survival support vector machine, SSVM)方法在一定程度上解决了这个问题。这两种方法不仅能将高维SNPs数据作为变量直接纳入模型进行预测,还能发现SNPs间的交互作用。截至目前,RSF和SSVM被广泛应用于疾病遗传风险的预后预测中[11]。实际研究与临床诊疗过程中,倾向采用相关生物检测技术研究已证实与该疾病有关的基因,因此,从候选基因组角度开展预后预测尤为必要。
本研究从全基因组和候选基因组角度,结合最新发现的AD建模策略并规避超高维数据对机器学习方法的影响,对比PRS与机器学习4种方法的第5年预后预测精度,可以为MCI发展为AD的疾病风险预测建模提供有效可行的建模方案。
1. 对象与方法
1.1 研究对象
数据来源于ADNI。ADNI是一项纵向多中心研究,旨在开发用于早期发现和跟踪AD的临床、影像学、遗传和生化生物标志物。本研究包括诊断时年龄>55岁的非西班牙裔白人MCI个体,结局事件是在5年随访期间由MCI发展为AD。通过控制人种、结局事件等,最终保留了429个MCI个体。经5年随访研究后,有130个MCI个体发展为AD患者,中位生存时间为36.60月。见表 1。
表 1 基本信息Table 1. Basic information变量 MCI(n=299) AD(n=130) 年龄/岁(x±s) 72.57±7.39 73.46±6.85 受教育程度(x±s) 15.97±2.87 16.09±2.91 性别[人数(占比/%)] 男 181(60.53) 81(62.30) 女 118(39.47) 49(37.70) 注:1. MCI:轻度认知障碍。2. AD:阿尔茨海默病。 1.2 研究方法
1.2.1 数据处理
使用Plink 1.9软件对满足下列条件的SNPs或个体进行剔除:(1)次要等位基因频率(minor allele frequency, MAF)≤5%;(2)对照组Hardy-Weinberg平衡检验的P < 10-6;(3)病例组Hardy-Weinberg平衡检验的P < 10-10;(4)SNPs基因型缺失率≥2%;(5)个体基因型缺失率≥1%。此外,通过去除连锁不平衡(linkage disequilibrium, LD)>0.250的SNPs来消除位点间的相关性,以保留具有统计学意义的SNPs。最终全基因组纳入了6 587 908个SNPs,候选基因组质控后纳入了20 372个SNPs。
1.2.2 预测模型
(1) PRS方法:方法1 C+T,C+T方法是最传统的PRS方法,首先通过对SNPs进行聚类减少LD以保留关联性较弱的SNPs,之后划分P值阈值以筛选出各阈值下P值最小的SNPs。PRS计算公式为:
$$ P R S_{P_{T, j}}=\sum\nolimits_{i=1}^m \beta_i G_{i, j} $$ (式(1)) 式(1)中,PT表示划分的P值阈值;j表示第j个体;i表示该阈值下纳入的SNPs的数量,i=1,2,…,m;βi表示SNPs的效应值;Gi, j表示SNPs的基因型,用{0,1,2}表示。本研究保留在500 kb的窗口内P值最小的SNPs,且去除r2>0.1的SNPs,其PT分别为1×10-8、1×10-7、1×10-6、1×10-5、1×10-4、0.001、0.01、0.1、0.5、1。方法2 PRS-CS,PRS-CS是基于贝叶斯框架,对SNPs效应值进行连续收缩先验估计的一种方法。其估计效应值的过程如下:
首先,在贝叶斯高维回归框架下建模:
$$ Y_{n \times 1}=X_{n \times m} \beta_{m \times 1}+\varepsilon_{n \times 1} $$ (式(2)) 式(2)中,Y是表型,X是基因矩阵,n和m分别表示样本量和SNPs的个数,β表示SNPs的效应值,ε是残差向量。β的先验密度表示为:
$$ p\left(\beta_j\right)=\int N(0, \psi) d G\left(\psi_j\right), j=1, 2, \cdots \cdots, m $$ (式(3)) 等价于$ \beta_j \mid \psi_j \sim N\left(0, \varphi \psi_j\right)$,ψj~g,式(3)中,φ是全局比例参数,控制模型的稀疏度;ψj是局部收缩参数,可以自适应的将小噪声压缩为0;g是绝对连续的密度函数,通过选择g对β实现连续收缩先验。
(2) 机器学习方法:方法1 RSF,RSF是一种用于对右删失数据进行分析的方法。通过Bootstrap法将原始数据有放回的随机抽取ntree个样本,并为每个样本形成一个二元决策树,在决策树的每个结点处,根据分裂准则将研究对象进行分类。本研究选用Log-Rank准则。其检验统计量为:
$$ L(x, c)=\frac{\sum\nolimits_{i=1}^n\left(d_{i, 1}-\frac{Y_{i, 1} d_i}{\gamma_i}\right)}{\sqrt{\sum\nolimits_{i=1}^n \frac{Y_{i, 1}}{\gamma_i}\left(1-\frac{Y_{i, 1}}{\gamma_i}\right)\left(\frac{Y_i-d_i}{Y_i-1}\right) d_i}} $$ (式(4)) 式(4)中,n是样本量,di, j是在时间ti时出现结局事件的人数,Yi, j表示在时间ti时刻处于结局事件的个体数,L(x, c)是节点分裂的度量,其值越大,表示分裂效果越好。此外,随机生存森林模型还可以根据重要性评分法(variable importance, VIMP)法和最小深度法对变量进行过滤。本研究通过VIMP法来筛选变量,将VIMP值>0的变量纳入模型,其值越大代表该变量与结局越相关。方法2 SSVM,SSVM是将边缘最大化的概念推广到生存数据中,通过构建间隔最大超平面实现分类问题,其目标函数为:
$$ \begin{gathered} min \cdot \frac{1}{2}|| \psi||^2+\gamma \sum\nolimits_{i=1}^n \xi_i, \\ \text { 服从 }-\left(y_i\left(\left\langle x_i, \psi\right\rangle+b\right)+\xi_i-1\right) \leqslant 0, \\ \text { 且 } \xi_i \geqslant 0, i=1, \cdots \cdots, n \end{gathered} $$ (式(5)) 式(5)中,ψ和b为调优参数,ξi为松弛变量,γ为控制最大间隔和误分类惩罚的正则化参数。本研究采用混合方法进行分析,因为本研究的特征变量远大于样本量,所以选用线性核函数。为了获得最大间隔超平面,惩罚项设为1。本研究先采用Cox比例风险模型对各变量进行单变量分析,以筛选出与结局有高度相关的SNPs,之后将筛选出的SNPs通过SSVM进行预测。
1.3 计算PRS
计算PRS时需要两个数据集:(1)Base数据:使用国际阿尔茨海默病基因组学项目(international genomics of alzheimer′s project, IGAP)的数据,这是一项基于全基因组关联的大型研究,通过阿尔茨海默病遗传学联盟(alzheimer disease genetics consortium, ADGC)、欧洲阿尔茨海默病倡议(the european alzheimer′s disease initiative, EADI)、基因组流行病学心脏和衰老研究队列联盟(cohorts for heart and aging research in genomic epidemiology consortium, CHARGE)、阿尔茨海默病遗传和环境风险联盟(genetic and environmental risk in alzheimer′s disease, GERAD)4个数据集Meta分析得出,包括21 982例AD病例和41 944例认知正常人群[12]。(2)Target数据:独立于Base数据,全基因组使用质量控制后的6 587 908个SNPs;候选基因组使用质量控制后的20 372个SNPs。为了防止人口分层带来的混杂,本研究通过EGENERATRA软件确定了特征值的P < 0.05的前5个主成分纳入模型计算PRS。载脂蛋白E(apolipoprotein E, APOE)的两个位点(rs7412, β=-0.47和rs429358, β=1.12)采用Leonenko等[13]的处理方式,即对这两个位点单独计算PRS,并将其与无APOE两个对应位点的PRS计算加权和。此外,年龄、性别和受教育年限已被确定为是MCI的主要危险因素,因此,将其作为协变量纳入模型进行预测[14]。
1.4 统计学方法
使用R 4.1.3软件和Python 3.8.5软件,以是否发生AD和发生时间为结局变量,构建C+T、PRS-CS、RSF和SSVM模型。为避免出现机会性结果,本研究使用十折交叉验证进行模型拟合,使用C指数作为模型的预测评价指标。检验水准α=0.05。
2. 结果
2.1 PRS与MCI发展为AD的关联
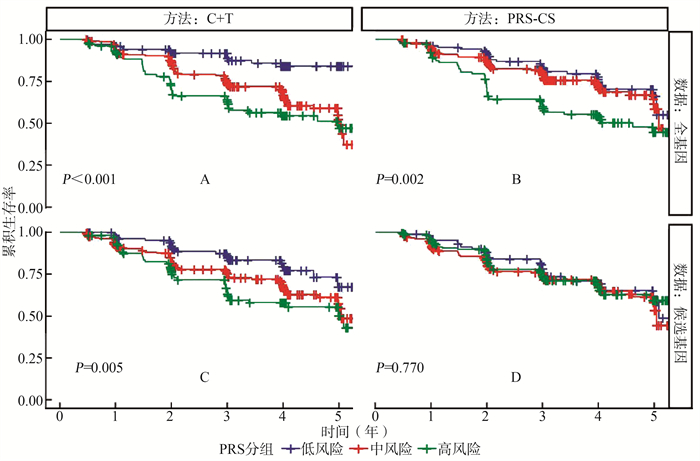
根据PRS分布的四分位数(< 25%,≥25%~75%,>75%)将个体分为3组, < 25%为低风险组,≥25%~75%为中风险组,>75%为高风险组。利用生存曲线与Log-Rank检验研究PRS与MCI发展为AD的相关性。在全基因组下,C+T方法计算出的风险评分与PRS-CS方法计算出的风险评分表明3组患者的生存曲线不同(P < 0.001),高风险组患者生存率低于低风险组患者,表明风险评分对AD具有一定的预测作用。但是在候选基因组下,PRS-CS方法计算的风险评分并不能说明3组患者的生存曲线不同(P=0.770)。见图 1。
 图 1 PRS与MCI发展为AD的K-M生存曲线1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. MCI:轻度认知障碍; 4. AD:阿尔茨海默病。Figure 1. K-M survival curves of PRS and MCI progressing into AD
图 1 PRS与MCI发展为AD的K-M生存曲线1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. MCI:轻度认知障碍; 4. AD:阿尔茨海默病。Figure 1. K-M survival curves of PRS and MCI progressing into AD2.2 PRS方法预测结果比较
在全基因组和候选基因组两种情况下分别用C+T和PRS-CS对MCI发展为AD的第5年生存情况进行预测,可以看出,四种情况下的C指数相差不大。对十折交叉验证的结果进行Welch检验的P值为0.68>0.05,尚不能说明4种情况下十折交叉验证的平均C指数存在差异。在利用PRS方法进行MCI发展为AD的预后预测中,全基因组和候选基因组计算出的PRS具有相同的预测效果,并且在该预测情境下,C+T方法和PRS-CS方法的表现相近,没有明显差别。但是相较于C+T方法,PRS-CS方法十折交叉验证结果的离散程度较小。见图 2、表 2。
 图 2 全基因组和候选基因组下PRS方法的十折交叉验证结果比较1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩。Figure 2. Comparison of ten-fold cross-validation results of PRS methods for whole genomes and candidate genomes表 2 PRS方法与机器学习方法十折交叉验证结果均值的多重比较Table 2. Multiple comparisons of the means of ten-fold cross-validation results between the PRS method and machine learning method
图 2 全基因组和候选基因组下PRS方法的十折交叉验证结果比较1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩。Figure 2. Comparison of ten-fold cross-validation results of PRS methods for whole genomes and candidate genomes表 2 PRS方法与机器学习方法十折交叉验证结果均值的多重比较Table 2. Multiple comparisons of the means of ten-fold cross-validation results between the PRS method and machine learning method方法Ⅰ 方法Ⅱ 95% CI P值 PRS-CS C+T -0.098 1~0.020 2 0.190 RSF -0.167 2~-0.048 9 0.001 SSVM -0.169 2~-0.050 9 0.001 C+T PRS-CS -0.020 2~0.098 1 0.190 RSF -0.128 3~-0.010 0 0.023 SSVM -0.130 3~-0.012 0 0.020 RSF PRS-CS 0.048 9~0.167 2 0.001 C+T 0.010 0~0.128 3 0.023 SSVM -0.061 2~0.057 2 0.946 SSVM PRS-CS 0.050 9~0.169 2 0.001 C+T 0.012 0~0.130 3 0.020 RSF -0.057 2~0.061 2 0.946 注:1. RSF:随机生存森林。2. PRS-CS:多基因风险评分-连续收缩。3. C+T: 聚类与阈值。4. SSVM:生存支持向量机。5. 多重比较的P值使用Bonferroni法进行校正。 2.3 PRS方法与机器学习方法预测结果比较
RSF和SSVM方法很难对全基因组进行处理,因此本研究仅将这两种方法应用于候选基因组,由上面结果可知C+T、PRC-CS方法在全基因组和候选基因组两种情况下的表现相同。所以RSF、SSVM、C+T和PRS-CS 4种方法在候选基因组下具有可比性。
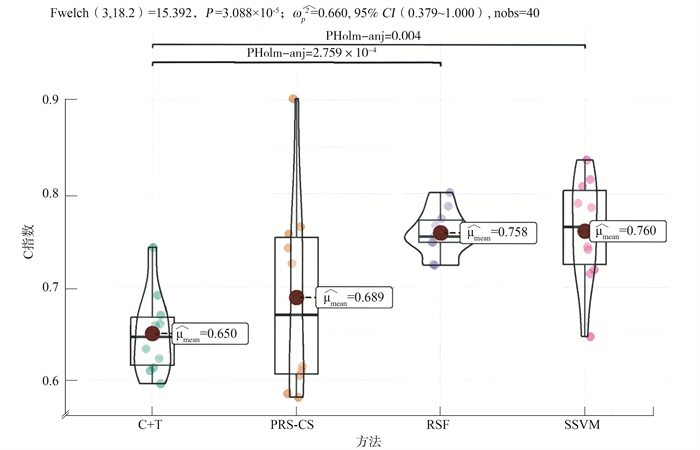
RSF、SSVM方法对MCI发展为AD的预后预测效能要远好于C+T、PRS-CS方法。Welch检验的P<0.05,说明4种方法的C指数差异均有统计学意义。见图 3。
 图 3 候选基因组下PRS方法与机器学习方法十折交叉验证结果比较1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. RSF:随机生存森林; 4. SSVM:生存支持向量机。Figure 3. Comparison of ten-fold cross-validation results between the PRS method and machine learning method under candidate genomes
图 3 候选基因组下PRS方法与机器学习方法十折交叉验证结果比较1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. RSF:随机生存森林; 4. SSVM:生存支持向量机。Figure 3. Comparison of ten-fold cross-validation results between the PRS method and machine learning method under candidate genomes十折交叉验证结果均值的多重比较,可以看出RSF与SSVM方法的C指数没有差异,P值为0.946,但是RSF方法十折交叉验证的结果更为集中。同时两个机器学习方法与两个PRS方法多重比较的P值均<0.05,RSF、SSVM方法在MCI发展为AD的预后预测研究中的性能表现要好于C+T、PRS-CS方法。见表 2。
3. 讨论
MCI发展为AD的预后预测的统计建模带来了诸多挑战,尤其是SNPs间存在的极其复杂的非线性关系。本研究从全基因组与候选基因组角度,比较PRS与机器学习两类建模方法对MCI发展为AD的预后预测性能,探索更为便捷可行的统计建模方案,为MCI发展为AD的精准诊疗提供可靠的统计方法学依据。
本研究根据PRS的四分位数进行分组并绘制生存曲线,发现在多数情况下PRS可以对患者进行区分。但是在候选基因组下,PRS-CS方法计算得到的风险评分并不能说明不同组患者的生存率存在差异。查阅资料发现,PRS-CS方法在样本量较小时预测精度较低[9]。本研究在质控后仅保留429个个体,可能对该方法造成了一定的影响。
无论在全基因组还是候选基因组下,C+T方法和PRS-CS方法比较的Welch检验表明C+T方法与PRS-CS方法的C指数之间的差异无统计学意义,在MCI发展为AD的第5年预后预测研究中,两种方法的预测性能相近,可以看出对于极难区分的MCI和AD,PRS-CS方法的效应值估计优势并不能体现。同时,各方法在两种情况下的预测性能也没有差异,全基因组和候选基因组计算出的PRS具有相同的预测效果。
从候选基因组角度,PRS方法的预测效果与全基因组数据相比较为一致,然而,机器学习方法的预测效果要优于PRS方法。因为AD的遗传结构不仅是简单的线性关系,还包括非线性关系,机器学习方法在筛选出重要SNPs的同时,还可以发现SNPs间的非线性特征。
本研究存在一定局限性:(1)样本量相对较少,目前尚不能开展针对AD的大样本研究。(2)AD的病因复杂,遗传和环境都是该病的重要因素。本研究局限于遗传因素对AD的影响。
综上所述,对于MCI发展为AD的第5年预后情况预测,PRS方法在全基因组和候选基因组下的表现相同,而同样适用于候选基因组的RSF、SSVM等机器学习方法的预测性能远好于PRS方法。所以本研究推荐使用机器学习方法进行MCI发展为AD的生存情况预测。
-

图 1 PRS与MCI发展为AD的K-M生存曲线
1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. MCI:轻度认知障碍; 4. AD:阿尔茨海默病。
Figure 1. K-M survival curves of PRS and MCI progressing into AD

图 2 全基因组和候选基因组下PRS方法的十折交叉验证结果比较
1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩。
Figure 2. Comparison of ten-fold cross-validation results of PRS methods for whole genomes and candidate genomes
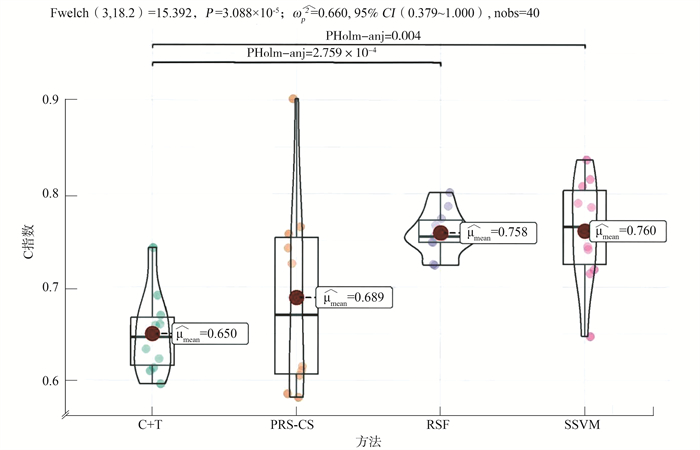
图 3 候选基因组下PRS方法与机器学习方法十折交叉验证结果比较
1. C+T: 聚类与阈值; 2. PRS-CS:多基因风险评分-连续收缩; 3. RSF:随机生存森林; 4. SSVM:生存支持向量机。
Figure 3. Comparison of ten-fold cross-validation results between the PRS method and machine learning method under candidate genomes
表 1 基本信息
Table 1. Basic information
变量 MCI(n=299) AD(n=130) 年龄/岁(x±s) 72.57±7.39 73.46±6.85 受教育程度(x±s) 15.97±2.87 16.09±2.91 性别[人数(占比/%)] 男 181(60.53) 81(62.30) 女 118(39.47) 49(37.70) 注:1. MCI:轻度认知障碍。2. AD:阿尔茨海默病。  下载: 导出CSV
下载: 导出CSV
表 2 PRS方法与机器学习方法十折交叉验证结果均值的多重比较
Table 2. Multiple comparisons of the means of ten-fold cross-validation results between the PRS method and machine learning method
方法Ⅰ 方法Ⅱ 95% CI P值 PRS-CS C+T -0.098 1~0.020 2 0.190 RSF -0.167 2~-0.048 9 0.001 SSVM -0.169 2~-0.050 9 0.001 C+T PRS-CS -0.020 2~0.098 1 0.190 RSF -0.128 3~-0.010 0 0.023 SSVM -0.130 3~-0.012 0 0.020 RSF PRS-CS 0.048 9~0.167 2 0.001 C+T 0.010 0~0.128 3 0.023 SSVM -0.061 2~0.057 2 0.946 SSVM PRS-CS 0.050 9~0.169 2 0.001 C+T 0.012 0~0.130 3 0.020 RSF -0.057 2~0.061 2 0.946 注:1. RSF:随机生存森林。2. PRS-CS:多基因风险评分-连续收缩。3. C+T: 聚类与阈值。4. SSVM:生存支持向量机。5. 多重比较的P值使用Bonferroni法进行校正。
下载: 导出CSV
-
[1] Nussbaum RL, Ellis CE. Alzheimer's disease and parkinson's disease[J]. N Engl J Med, 2003, 348(14): 1356-1364. DOI: 10.1056/NEJM2003ra020003. [2] Petersen RC. Mild cognitive impairment[J]. Continuum (Minneap Minn), 2016, 22(2 Dementia): 404-418. DOI: 10.1212/CON.0000000000000313. [3] Li HT, Yuan SX, Wu JS, et al. Predicting conversion from MCI to AD combining multi-modality data and based on molecular subtype[J]. Brain Sci, 2021, 11(6): 674. DOI: 10.3390/brainsci11060674. [4] Mamani NM. Machine learning techniques and polygenic risk score application to prediction genetic diseases[J]. ADCAIJ, 2020, 9(1): 5-14. DOI: 10.14201/ADCAIJ20209154. [5] Baker E, Escott-Price V. Polygenic risk scores in Alzheimer's disease: current applications and future directions[J]. Front Digit Health, 2020, 2: 14. DOI: 10.3389/fdgth.2020.00014. [6] Li J, Lu Q, Wen Y. Multi-kernel linear mixed model with adaptive lasso for prediction analysis on high-dimensional multi-omics data[J]. Bioinformatics, 2020, 36(6): 1785-1794. DOI: 10.1093/bioinformatics/btz822. [7] Privé F, Vilhjálmsson BJ, Aschard H, et al. Making the most of clumping and thresholding for polygenic scores[J]. Am J Hum Genet, 2019, 105(6): 1213-1221. DOI: 10.1016/j.ajhg.2019.11.001. [8] Ge T, Chen CY, Ni Y, et al. Polygenic prediction via Bayesian regression and continuous shrinkage priors[J]. Nat Commun, 2019, 10(1): 1776. DOI: 10.1038/s41467-019-09718-5. [9] Ishwaran H, Kogalur UB, Blackstone EH, et al. Random survival forests[J]. Thorac Oncol, 2008, 2(3): 841-860. DOI: 10.1214/08-AOAS169. [10] Evers L, Messow CM. Sparse kernel methods for high-dimensional survival data[J]. Bioinformatics, 2008, 24(14): 1632-1638. DOI: 10.1093/bioinformatics/btn253. [11] Deng Y, Cheng S, Huang H, et al. Toward better risk stratification for implantable cardioverter-defibrillator recipients: implication of machine learning models[J]. J Cardiovasc Dev Dis, 2022, 9(9): 310-325. DOI: 10.3390/jcdd9090310. [12] Kunkle BW, Grenier-Boley B, Sims R, et al. Genetic meta-analysis of diagnosed Alzheimer's disease identifies new risk loci and implicates Aβ, tau, immunity and lipid processing[J]. Nat Genet, 2019, 51(3): 414-430. DOI: 10.1038/s41588-019-0358-2. [13] Leonenko G, Baker E, Stevenson-Hoare J, et al. Identifying individuals with high risk of Alzheimer's disease using polygenic risk scores[J]. Nat Commun, 2021, 12(1): 4506. DOI: 10.1038/s41467-021-24082-z. [14] Ritchie K. Mild cognitive impairment: an epidemiological perspective[J]. Dialogues Clin Neurosci, 2004, 6(4): 401-408. DOI: 10.31887/DCNS.2004.6.4/kritchie. 期刊类型引用(1)
1. 刘莹,邹金婷,陈赛苦,殷大鹏,王兴任,江娟,周脉耕,张东献,何滨. 海南省2019年居民死因顺位前十位疾病负担研究. 现代预防医学. 2024(15): 2713-2718 .  百度学术
百度学术其他类型引用(0)
-
 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 514
- HTML全文浏览量: 145
- PDF下载量: 47
- 被引次数: 1